在2021年山东大学软件学院暑期实训的骨刻文字数字化识别项目中,我们小组进入了软件开发的关键阶段。本阶段的核心任务是将前期设计的算法模型和数据处理流程,转化为一个可实际运行、具备用户交互功能的软件系统。作为软件学院的学生,这次实训不仅是对专业知识的综合应用,更是对“山东软件开发”实践能力的一次深度锤炼。
一、开发环境与技术栈选择
项目基于Python语言进行开发,主要利用了深度学习框架PyTorch。考虑到骨刻文字图像处理的特殊性,我们选用了OpenCV进行图像预处理,如去噪、增强和分割。后端服务采用Flask框架搭建,以实现模型推理的API接口;前端则使用HTML、CSS和JavaScript构建简洁的交互界面,方便用户上传骨刻图像并查看识别结果。数据库选用MySQL,用于存储用户数据、图像元信息及识别记录。整个开发过程在山东大学提供的实验室服务器上进行,确保了计算资源的稳定。
二、核心功能模块开发
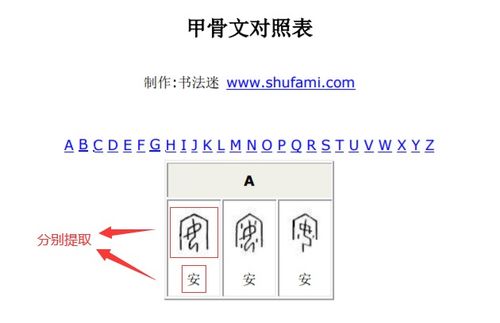
- 图像预处理模块:我们开发了自动化的图像处理流水线,能够对用户上传的骨刻拓片图像进行灰度化、二值化、轮廓检测和单字切割。这一模块的优化直接影响了后续识别的准确性,我们通过多次实验调整参数,以适配不同质量、不同来源的骨刻图像。
- 模型集成与推理模块:将训练好的卷积神经网络(CNN)模型集成到系统中是核心挑战。我们编写了模型加载和推理脚本,确保其在服务器环境中能够高效、稳定地运行。为了提高响应速度,我们实现了缓存机制,对常见字符的识别结果进行临时存储。
- Web应用开发:基于Flask,我们构建了RESTful API,定义了诸如
/upload(上传图像)、/predict(执行识别)、/history(查询历史)等端点。前端界面设计注重实用性,提供了清晰的文件上传区域、识别结果展示区(包括原图、处理后的图像、识别出的文字及可信度),以及简单的历史记录查询功能。
三、开发过程中的挑战与解决
- 性能瓶颈:初期,单次识别耗时较长。通过分析,我们发现图像预处理和模型加载是主要瓶颈。解决方案包括:对预处理算法进行代码优化;采用模型预热策略,在服务启动时即加载模型至内存;对于批量处理需求,引入简单的队列机制。
- 系统兼容性:确保软件在不同浏览器和操作系统上都能正常运行。我们进行了跨平台测试,并对前端代码进行了适配调整。
- 团队协作:作为山东软件开发团队,我们使用Git进行版本控制,遵循敏捷开发流程,定期召开站会同步进度,并使用Jira管理开发任务和Bug,有效提升了协作效率。
四、与收获
通过这一阶段的软件开发实战,我们深刻体会到将学术算法转化为实际产品的完整流程。不仅巩固了Python Web开发、深度学习部署、数据库设计等专业知识,更在实践中学习了项目管理和团队协作。此次针对骨刻文字这一独特文化遗产的数字化开发,也让我们认识到软件技术赋能传统文化研究的重要价值。作为山东大学软件学院的学生,这次实训是一次宝贵的“山东软件开发”经验,为我们未来从事相关领域的工作奠定了坚实的基础。
(注:本笔记为学习过程记录,涉及的具体代码与架构细节已做简化处理。)